本日の TIL は、コンテナ間でデータをやりとりするために名前付きパイプ (named pipe, FIFO) を使ってみたことでわかった利点と注意点です。
先日、ある PoC のための簡単な web アプリケーションを作っている際に、2つのコンテナ間でちょっとしたデータのやりとりをしたい場面がありました。具体的には下の図のように、 ブラウザから入力されたテキストを web のコンテナで受け取り、それを別のコンテナ (仮に processor とします) に投げて処理させ、その結果を受け取り、最後にブラウザに表示する必要があります。
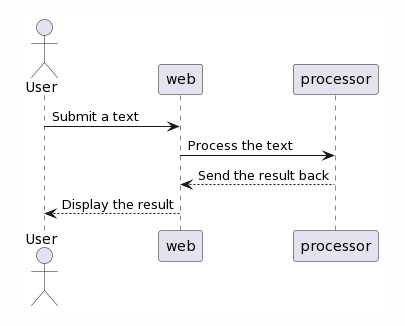
web と processor でのやりとりをどう実装するか少し検討してみた結果、名前付きパイプを使ってみることにしました。なぜなら、今回の用途には十分に感じられ、かつ簡単に実装できそうだったからです。ただし、もしこれが production 環境で向こう何年か動き続けるものだとしたら話は変わってきそうです。お手軽さを選択してみることができた背景には、このアプリケーションが主にプロジェクトメンバー達のラップトップ上で動く試作品で、通信方法もこのときの主眼ではなかったという点がありました。
そういうわけで実際に名前付きパイプを使ってみたところ、結論としては、確かにこの方法は簡単でした。また、シェルだけで実装できるため、実行環境に追加のソフトウェアをインストールする手間も不要という手軽さでした。しかし一方で、簡素な仕組みであるゆえに、少しでもデータのやりとりが複雑なものになると、より高級な既存のプロトコル (HTTP など) を採用する場合とくらべて、必ずしも手軽とは言いきれないということがわかりました。また、パイプを使う上での特有の注意点も見えてきました。
ここからは、より具体的な説明をするために、実際に動く例を使ってみたいと思います。その中で、この方法の注意点にも触れていきたいと思います。
どう実装したか
話を簡単にするために、冒頭の processor でやっていた実際のテキスト処理を、記事向けにスペルチェックツール aspell(1) で置き換えたサンプルアプリケーションを作ってみました。ブラウザから見ると「入力したテキストを submit したら、スペルチェックされた結果が画面に表示される」という動作になります。処理の流れは冒頭の図の通りです。
名前付きパイプを使っての web と processor との間のデータの流れは次のようなイメージです。図のように、input/output それぞれにひとつずつパイプを使います。
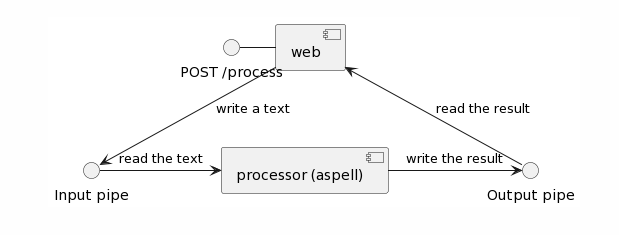
実装に必要なのは次の4つのファイルです。
$ tree
.
├── docker-compose.yml
├── processor
│ └── worker.sh
└── web
├── index.html
└── server.rb
2 directories, 4 files
2つのコンテナ (web と processor) は Docker Compose で管理します。以下の docker-compose.yml に、各コンテナや volume の情報などを設定します。
x-env: &env - PROC_INPUT=/var/run/sample/proc-in - PROC_OUTPUT=/var/run/sample/proc-out - PROC_LOCK=/var/run/sample/proc.lock volumes: ipc: services: web: image: ruby:3.1-slim ports: ['4567:4567'] init: true working_dir: /work environment: *env command: ['ruby', 'server.rb'] volumes: - type: volume source: ipc target: /var/run/sample - type: bind source: ./web target: /work processor: image: r.j3ss.co/aspell init: true working_dir: /work environment: *env entrypoint: ['/bin/ash'] command: ['/work/worker.sh'] volumes: - type: volume source: ipc target: /var/run/sample - type: bind source: ./processor target: /work
名前付きパイプではファイルを読み書きする要領で通信ができるので、シェルさえあれば実装できます。コンテナ間でやりとりする場合は、名前付きパイプの共有をどうするかを考える必要が出てきますが、実は普通のファイルと同様に volume で共有できます。上記では、そのために定義した volume ipc を各コンテナの /var/run/sample に配置しています。また、名前付きパイプのファイルパスなどを環境変数として定義しています。それぞれ次の用途です。
PROC_INPUT: 入力用の名前付きパイプ。PROC_OUTPUT: 出力用の名前付きパイプ。PROC_LOCK: 排他制御 (後述) に使うための普通の空ファイル。
それでは各実装について、入力から出力まで処理の流れに沿って見ていきましょう。web 側は Sinatra で実装しました。 index.html は POST /process にテキストを投げるためのフォームです (ここでは省略します; gist)。
require 'bundler/inline' gemfile do source 'https://rubygems.org' gem 'sinatra' gem 'webrick' end set :static, true set :public_folder, __dir__ set :bind, '0.0.0.0' get '/' do content_type 'text/html' send_file File.join(settings.public_folder, 'index.html') end post '/process' do content_type 'text/plain' File.open ENV['PROC_LOCK'] do |lock| lock.flock File::LOCK_EX output = Thread.new { File.read(ENV['PROC_OUTPUT']) } File.write ENV['PROC_INPUT'], request.body.read output.value end end Sinatra::Application.run!
post '/process' のブロックで、次のような流れでパイプへの読み書きをしてブラウザにレスポンスを返しています。
- 出力用パイプから読み込みを別スレッドで開始。
- 入力用ファイルにテキストをすべて書き込む。
入力を書き込む前に出力を別スレッドで読み始めているのは、大きなテキストを渡す際に書き込みが止まってしまうことを防ぐための対応です。というのも、パイプには容量があり、その容量を超えるサイズのテキストを書き込むことはできません (ブロックするかエラーになる)。そのため、書き込みと同時に出力側からの読み出しも行なうことで、データの流れが止まらないようにしています。
また念のため、入力の書き込みから出力の読み込みまでの間に別のリクエストからの邪魔が入ることがないよう、IO#flock で排他制御をしています。ロック取得のために (入力用/出力用のパイプではなく) わざわざ別ファイルを使っているのは次のような理由で、名前付きパイプの特性上ロックの用途には使いづらいと判断したためです。
- 入力用のパイプに流したデータの末尾 (EOF) を読み出し側に知らせるには、書き込み側でファイルを閉じるという操作が必要。しかし、ファイルを閉じるということはロックも手放してしまうことになる。ロックは出力用のパイプを読み終わるまで手放したくない。
- 出力用のパイプを読み込むために開くには、書き込み側からもファイルを開く必要がある。しかし、ロックを取得したいタイミングは書き込み側がファイルを開くより前。
さて、上記でパイプへ書き込まれたテキストは、processor が worker.sh で読み込みます。そのテキストを入力として aspell を実行し、結果を出力用のパイプに書き込みます。
#!/bin/bash set -e test -p "$PROC_INPUT" || mkfifo "$PROC_INPUT" test -p "$PROC_OUTPUT" || mkfifo "$PROC_OUTPUT" test -f "$PROC_LOCK" || touch "$PROC_LOCK" set +e while : do echo "Waiting input..." aspell -a < "$PROC_INPUT" > "$PROC_OUTPUT" done
最初のあたりでは、各ファイルがまだ存在しなければ作成しています。あとはパイプに入力がある度に aspell をひたすら繰り返すだけです。
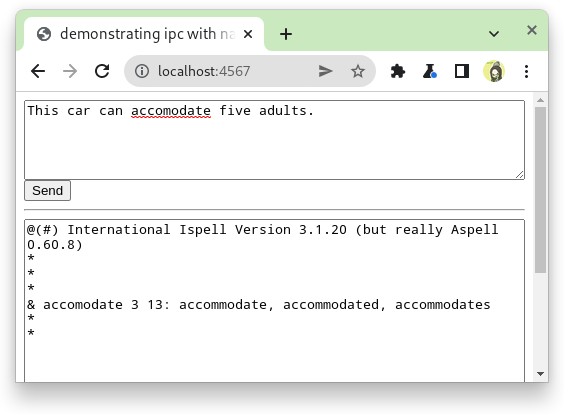
これで一通り準備ができました。起動してブラウザからテキストを送ると、期待した通り、スペルチェック結果が確認できます。ブラウザのスペルチェッカも反応しており、正しそうです。
どんな問題があるか
名前付きパイプを使うことで、サーバ側の実装をほぼシェルだけでお手軽に済ませることができました。簡単な仕組みで、手間もかからず、うまく動いています。しかし、この方法には少なくともひとつ潜在的な問題がありました。それは、現状では標準入出力のやりとりしかできないという点です。たとえば aspell の実行途中にエラーが発生し異常終了したとしても、この仕組みでは終了ステータスを受け取る方法がないので、気づくことができません。また、標準エラー出力に何かエラーが出ている場合も、出力用のパイプに流しているのは標準出力だけなので、web からはわかりません。
ここからもし標準入出力以外のデータをやりとりしたくなった場合には、そのための仕組みを用意する必要があります。例えば、出力用のパイプを増やせば終了ステータスや標準エラー出力も受け取れるようになります。または、パイプでやりとりするデータを単なるバイトストリームではなく、JSON のような構造化された形にすることでも対応はできそうです。とはいえ、もともとお手軽さを求めて選んだ方法が、こうなってくるとあまりお手軽に感じられなくなってきました。むしろ、 Sinatra か Flask でも入れて HTTP でやりとりした方がまだ楽かもしれません。
また、この仕組みのまま時間あたりの処理能力を上げることが難しいという点も、用途によっては問題となりそうです。現状では、外部コマンドの実行という比較的コストの高い処理をひとつずつ順番に実行しているからです。もしこれを parallel に複数実行できれば処理能力を上げることはできそうですが、その場合もやはり、現状よりも複雑になることは避けられません。
おわりに
今回わかったことは大きく分けて2つです。
- 名前付きパイプはちょっとした通信をお手軽に実装する手段として便利。ただし、やりとりが少しでも複雑になると相応の手数が必要になる。
- 名前付きパイプは普通のファイルと似ているが、使い方にコツがある。
- パイプには容量があり、流れないと詰まる。
- データの末尾 (EOF) を読み込み側に知らせるには、書き込み側がファイルを閉じる必要がある。
- パイプを開くには、反対側からも開く必要がある。
使い方が分かってしまえばお手軽な半面、複雑なことは自前でやる必要があるので大変。だから先が読めない状況では、はじめからより高級な既存のプロトコルを使った方がいいというのが今回の感想です。
参考
- https://man7.org/linux/man-pages/man7/pipe.7.html
- https://linux.die.net/man/1/aspell
- https://linux.die.net/man/3/open
- https://www.lexico.com/grammar/common-misspellings
- https://unix.stackexchange.com/questions/68146/what-are-guarantees-for-concurrent-writes-into-a-named-pipe
- https://stackoverflow.com/questions/4624071/pipe-buffer-size-is-4k-or-64k