こんにちは、永和システムマネジメントに新卒で入社して4年目になりました swamp09 です。
この記事では、以前関わったRailsプロジェクトの default_scope のユースケースと実装例の話をします。
ユーザーが記事を投稿したり、記事にコメントしたりするWebサービスがあり、Twitterのようにユーザーが他のユーザーをブロックする機能がありました。
ブロックすると、ブロックしたユーザーからはブロックされたユーザーの投稿した記事やコメントが一切非表示になります。このブロックのロジックを default_scope で書けるとコーディングが楽になりそうだなぁとプロジェクトメンバーと話していました。
ただ、リクエストごとに異なるログインユーザーのブロックされたユーザーを非表示にするのは default_scope でうまく書けない、というところで悩んでいました。
そんな時に見つけたのが ActiveSupport::CurrentAttributes でした。
ActiveSupprt::CurrentAttributes ではリクエストごとの属性をシステム全体で簡単に利用できるよう保持できます。これを使って上記のような default_scope を書けるのではと思いました。
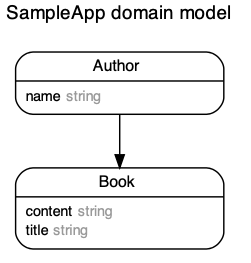
具体例をRailsチュートリアル第6版のサンプルアプリを元にコードで示します。sample_appにはUserとMicropostというモデルがあります。
class User < ApplicationRecord has_many :microposts, dependent: :destroy end class Micropost < ApplicationRecord belongs_to :user end
sample_appに追加でユーザーが他のユーザーを非表示にするためのブロック機能を追加していきます。
# Blockモデルを追加する class Block < ApplicationRecord belongs_to :blocker, class_name: "User" belongs_to :blocked, class_name: "User" validates :blocker_id, presence: true validates :blocked_id, presence: true end # UserモデルにBlockモデルとの関連を追加する class User < ApplicationRecord has_many :microposts, dependent: :destroy has_many :active_blocks, class_name: "Block", foreign_key: "blocker_id", dependent: :destroy has_many :blocking, through: :active_blocks, source: :blocked has_many :passive_blocks, class_name: "Block", foreign_key: "blocked_id", dependent: :destroy has_many :blockers, through: :passive_blocks, source: :blocker end
Blockモデルはsample_appのRelationshipモデルとほぼ同じです。
これに ActiveSupport::CurrentAttributes を用いてリクエストごとの default_scope を設定していきます。
# app/models/current.rb を追加する class Current < ActiveSupport::CurrentAttributes attribute :blocking_ids end # app/controllers/concerns/hide_blocking_user.rb を追加する module HideBlockingUser extend ActiveSupport::Concern included do before_action :set_current end private def set_current Current.blocking_ids = current_user&.blocking&.ids end end # ブロック機能が関わるControllerでconcernをincludeする class UsersController < ApplicationController before_action :logged_in_user, only: [:index, :edit, :update, :destroy, :following, :followers] before_action :correct_user, only: [:edit, :update] before_action :admin_user, only: :destroy # concernをincludeする include HideBlockingUser def index @users = User.paginate(page: params[:page]) end end # MicropostモデルとUserモデルのdefault_scopeを書き換える class Micropost < ApplicationRecord belongs_to :user has_one_attached :image default_scope do if Current.blocking_ids.present? where.not(user_id: Current.blocking_ids).order(created_at: :desc) else order(created_at: :desc) end end end class User < ApplicationRecord has_many :microposts, dependent: :destroy default_scope do where.not(id: Currnet.blocking_ids) if Current.blocking_ids.present? end end
以上のようにして、HideBlockedUser を include したControllerであれば default_scope を使ったブロック機能が使えるようになりました。
まとめ
リクエストごとに default_scope を指定したい、というユースケースはあまり出会うことはないかもしれませんが、ActiveSupprt::CurrentAttributes を使えば実装できることがわかりました。実際に使うかどうかは別として…
CurrentAttributesのドキュメントにも注意点が書かれていますが、CurrentAttributes を使う際はグローバルな値をいろんなところからアクセスできるようになるので、慎重に扱う必要があるかと思います。
ブロック機能を追加したコードは GitHub に置きました。なにかの参考になれば幸いです。